



La mise en production représente une étape cruciale dans la vie d'un projet, marquant son entrée dans le monde réel. Après avoir soigneusement dimensionné l'infrastructure à l'aide de tests de montée en charge et de projections d'utilisation, il est temps de rendre le projet pleinement opérationnel pour les utilisateurs. Cela implique de s'assurer de son bon fonctionnement, tout en surveillant et en détectant les éventuels problèmes à différents niveaux pour garantir une expérience utilisateur optimale.
Qu’est-ce que le Monitoring Post-Mise en Production ? Pourquoi faire et quelle est son importance ?
Le monitoring post-mise en production comprend :
- Surveillance continue des performances : En observant de près les performances du serveur, des bases de données, du réseau et des applications, les équipes peuvent détecter les problèmes potentiels dès qu'ils surviennent.
- Analyse en temps réel des données : La collecte et l'analyse en temps réel des données permettent d'identifier les tendances, les pics d'activité et les comportements anormaux, facilitant ainsi la prise de décision rapide.
- Gestion des logs et des alertes : La gestion des logs et la mise en place d'alertes permettent de suivre les événements importants, de diagnostiquer les problèmes et de réagir rapidement en cas d'incident.
- Optimisation des ressources : En surveillant l'utilisation des ressources telles que la mémoire, le processeur et le stockage, les équipes peuvent optimiser les configurations et les allocations pour garantir des performances optimales.
- Amélioration continue : Le monitoring post-mise en production offre des données précieuses pour l'amélioration continue de l'application, en identifiant les zones à optimiser et en guidant les décisions futures en matière de développement et de déploiement.
En mettant en œuvre ces pratiques de monitoring, les équipes peuvent assurer la stabilité, la fiabilité et les performances de leur application tout au long de son cycle de vie.
Quels outils utiliser ?
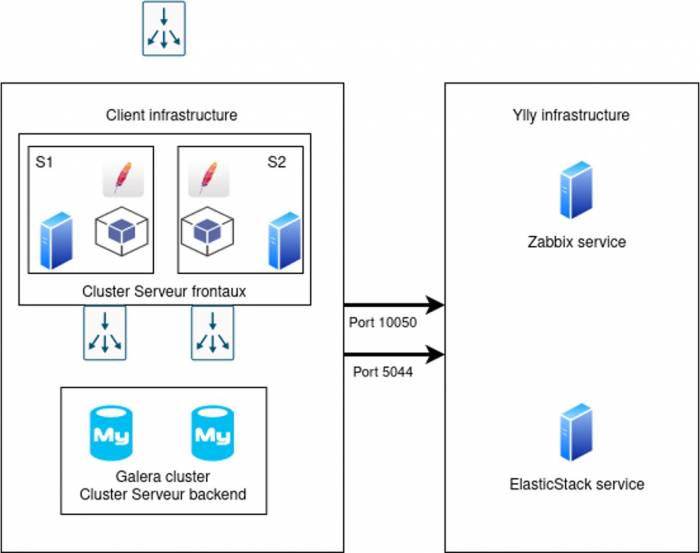
Chez Ylly, nous utilisons 2 outils pour réaliser le monitoring de nos applications web :
![]()

Zabbix
Grâce à Zabbix, nous pouvons surveiller en temps réel la santé de notre parc d'équipements, comprenant notamment des serveurs, des routeurs, et bien d'autres. Cette surveillance englobe diverses données telles que la charge du processeur, l'utilisation de la mémoire RAM, ainsi que l'espace disponible sur les partitions des disques.
Cet outil s'avère indispensable pour intervenir promptement sur le matériel ou les logiciels sous-tendant notre application. Voici quelques cas pratiques illustrant son utilité :
- Ajustement de la puissance matérielle suite à une augmentation significative de l'activité du projet.
- Redémarrage d'un service en cas de dysfonctionnement.
ElasticStack
ElasticStack offre une solution complète pour l'analyse statistique des logs générés par les applications et les projets. En agrégeant ces données, nous obtenons une vision globale des applications, ce qui nous permet d'identifier les problèmes récurrents, de surveiller l'activité des projets et de comprendre les fonctionnalités les plus sollicitées.
Voici quelques exemples concrets d'utilisation :
- Analyse des logs Symfony pour détecter les erreurs et les informations pertinentes liées aux besoins fonctionnels de l'application.
- Analyse des logs HTTP pour suivre l'utilisation de l'application, y compris les URL, les codes de réponse, et les temps d'exécution.
Zabbix et ElasticStack nous permettent de recouper les informations, ouvrant ainsi la voie à une analyse plus poussée des problèmes de production. En combinant les données de surveillance matérielles et logicielles fournies par Zabbix avec les analyses statistiques des logs proposées par ElasticStack, nous obtenons une vision complète de la santé et des performances de notre infrastructure et de nos applications.
Cas Pratique
Un nouveau projet web Symfony (réalisation d’une API) est sur le point d'être achevé. Nos administrateurs système ont récemment terminé l'installation du projet selon le schéma suivant :
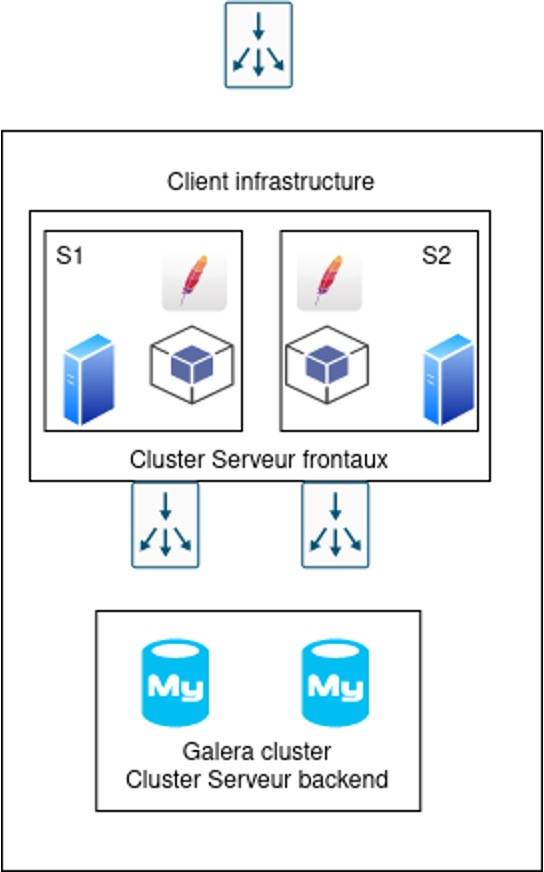
Chaque serveur a un rôle bien défini. Pour Zabbix, nous configurons chaque machine avec les templates correspondants :
- Serveurs frontaux : template Linux, HTTP, PHP
- Serveurs backends : template Linux, MySQL, Galera
Cette configuration nous permet d'obtenir des métriques et de surveiller les ressources consommées par le système pour chaque serveur via le template Linux, ainsi que des métriques spécifiques à chaque rôle.
Pour ElasticStack, nous suivons une approche similaire en activant les logs sur Filebeat en fonction du rôle des machines :
- Serveurs frontaux : logs d'accès et d'erreur du serveur HTTP, logs d'accès et d'erreur généraux de PHP, logs applicatifs
- Serveurs backends : logs généraux de MySQL, logs d'erreur, requêtes lentes
Les bonnes pratiques et stratégies avancées pour une optimisation du Monitoring Post-Mise en Production
Conseils de bonnes pratiques
- Configuration des alertes : Définissez des alertes pertinentes et bien calibrées pour être notifié en cas de dépassement de seuils critiques, mais évitez les alertes inutiles qui pourraient entraîner une fatigue ou une désensibilisation de l'équipe.
- Gestion des seuils : Établissez des seuils basés sur des métriques réalistes et adaptez-les au fur et à mesure de l'évolution de l'application. Évitez les seuils trop rigides qui déclenchent des alertes fréquentes ou trop souples qui laissent passer des problèmes significatifs.
- Sélection des métriques à surveiller : Identifiez les métriques clés qui sont les plus pertinentes pour votre application et vos objectifs métier. Priorisez la surveillance des métriques liées à la performance, à la disponibilité et à l'expérience utilisateur.
Analyse des tendances et prévisions
- Importance de l'analyse des tendances : Suivez l'évolution des métriques sur le long terme pour repérer les tendances significatives, telles que les pics saisonniers ou les changements de comportement. Cela permet d'anticiper les problèmes potentiels avant qu'ils ne deviennent critiques.
- Utilisation de la prévision : Utilisez des techniques de prévision pour estimer les futurs niveaux de charge, de trafic ou de demande. Cela permet de planifier les ressources nécessaires et d'éviter les interruptions de service dues à une capacité insuffisante.
Évolutivité et gestion des performances
- Surveillance des goulets d'étranglement : Identifiez les composants critiques qui sont susceptibles de devenir des goulets d'étranglement en cas de montée en charge. Surveillez de près ces composants et prenez des mesures proactives pour optimiser leur performance et leur évolutivité.
- Optimisation des ressources : Utilisez les données de monitoring pour optimiser l'utilisation des ressources, telles que la mémoire, le CPU et le stockage, en les dimensionnant correctement et en les répartissant de manière équilibrée entre les différents composants de l'infrastructure.
En conclusion, la mise en œuvre d'un monitoring post-mise en production efficace, combinant des bonnes pratiques, une analyse proactive des tendances, une attention à la sécurité et à la conformité, ainsi qu'une gestion optimale des performances, est essentielle pour garantir la fiabilité, la stabilité et la sécurité des applications et des systèmes en production. En suivant ces principes et en adoptant une approche proactive, les équipes peuvent anticiper les problèmes, optimiser les ressources et offrir une expérience utilisateur optimale tout au long du cycle de vie des applications.
Souhaitez-vous sécuriser votre infra et assurer la sérénité de vos équipes ?
Contactez-nous dès aujourd'hui et laissez nos experts vous guider pour donner vie à votre vision.



